
Navigating the Future with Microsoft Sentinel Data Lake - Are you planning to enable Sentinel Data Lake in your environment?
July 2025 and the Sentinel Data Lake is GA . . . Well almost! This is just the start. Data = Gold.

Well, Hello, Bonjour, Hola, Ciao!
It’s been a minute! Actually, exactly four months today since my last blog post. Life has certainly kept me on my toes: a young family, summer holidays, a busy security practice, four fantastic Experts Live UK - Microsoft Community Events meet-ups, and to top it all off, I've been deep into writing a brand-new Sentinel Technical Publication with José Lázaro ! Keep your eyes peeled, it’s coming your way very soon.
I’m excited to be back! If you enjoy my blogs, insights, and tips, please do share and subscribe. We're closing in on 1,000 followers!
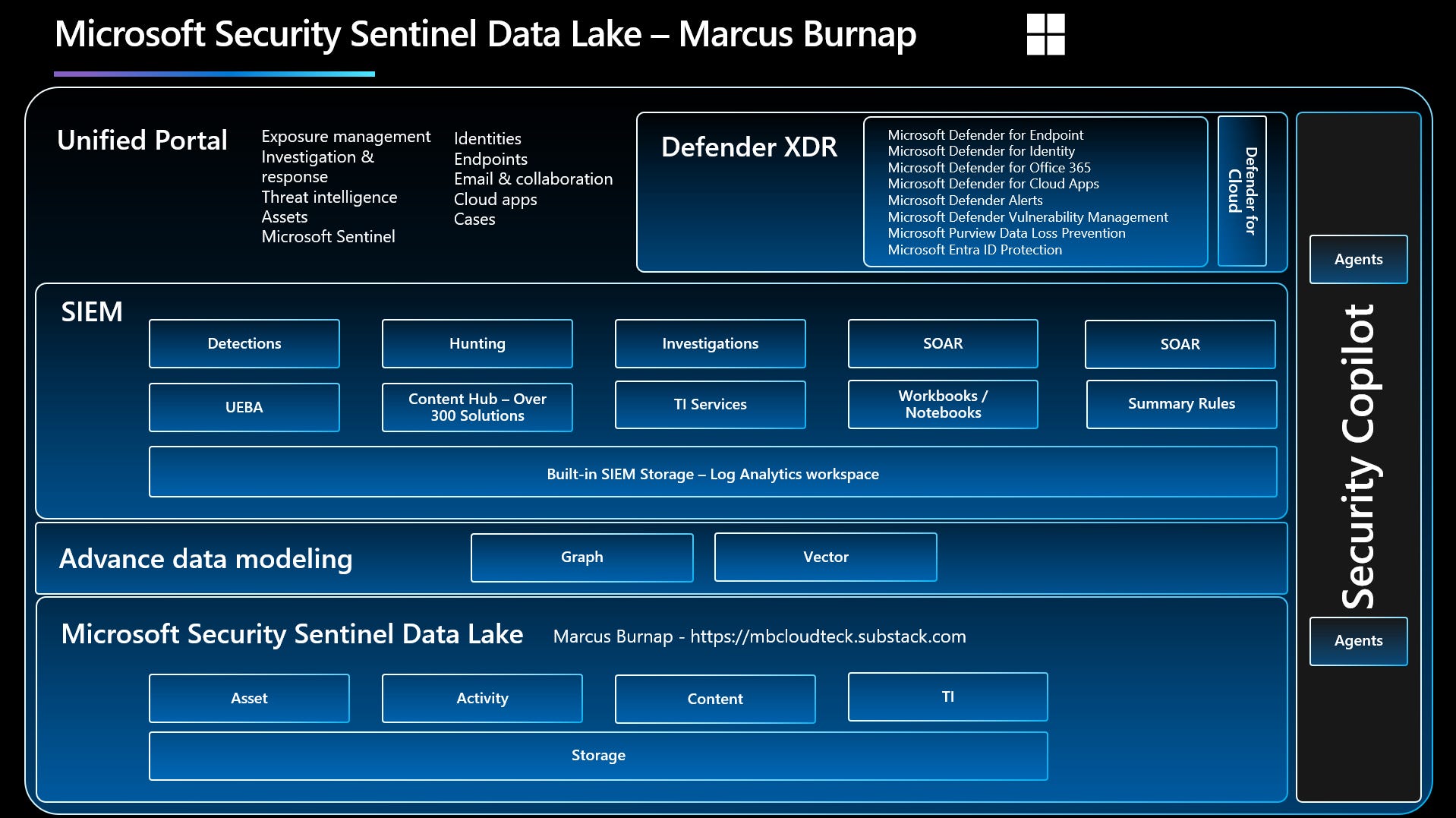
Big things have been happening in the Sentinel space, actually, even bigger than that, in the entire Microsoft Security Data landscape. While this Security Datalake development carries "Sentinel" in its name, it's about far more than just Sentinel itself. This innovation/change is set to power a whole new generation of Microsoft security capabilities, reaching across the entire ecosystem.
I first “officially” encountered this shift in data architecture during Microsoft Ignite in November 2024. A Product Manager at the time shared an early vision of what would eventually become Sentinel Data Lake. The moment it was confirmed as a serious direction being explored, it immediately sparked a wave of ideas. For one, it signaled Microsoft's intent to reach parity with approaches already adopted by competitors like GCP. More importantly, it acknowledged what many of us had long seen as a fundamental gap in the platform.
Since then, I’ve been envisioning the endless possibilities this architecture unlocks, from new extensibility options to entirely new classes of features within the Microsoft Security ecosystem. Of course, it’s been both exciting and frustrating, exciting to explore the potential, frustrating to keep those thoughts under wraps due to MVP and Partner NDA constraints. But now, with the official launch, the conversation can finally begin.
Effective security fundamentally relies on knowing exactly what you’re protecting. This is going to become very apparent with the new Exposure Management modules in Defender, especially since Defender transforms every endpoint device into an intelligent sensor that continuously monitors and collects security signals across your entire ecosystem, and even beyond. This will only improve and gather more data over time.
This is a crucial concept to grasp. Exposure management is just as important as identity management, yet, up until now, it’s something Microsoft hasn’t handled particularly well. The data layer was I imagine a key blocker.
Jumping ahead slightly, since this topic clearly deserves its own detailed blog post or video, the new Security Data Lake provides the underlying foundation for collecting this type of high-volume, lower-fidelity log data at scale. This foundation will unlock powerful features down the line, such as Smart Device Isolation and trend-based investigations spanning 12 to 24 months.
Based on the volume of data, it will also allow and enable new types of Graph and vector-based data modelling.
One area I’m particularly keen to understand better is whether Microsoft will continue to recommend separating operational performance data from security data, which has long been considered a best practice to reduce noise and control costs in traditional SIEM architectures. Given the scale, flexibility, and managed nature of the new Sentinel Data Lake, it raises an important question: will there be updated guidance around collecting non-security telemetry, especially at enterprise scale? It would be interesting to see whether Microsoft introduces new ingestion strategies or reference architectures that allow performance and operational data to benefit from the same efficiencies. If anyone has come across details on this, I’d love to hear more.

Traditional Security Information and Event Management (SIEM) platforms often require difficult compromises: retain all logs and absorb high costs, or limit retention and risk losing crucial investigative data.
In response to this long-standing challenge, Microsoft announced the public preview of Sentinel Data Lake in July 2025—a new, scalable, cloud-native approach to security data storage and analysis within Microsoft Sentinel.
A Paradigm Shift in Data Architecture
Redefining Low-Level Design Decisions around retention
Sentinel Data Lake is purpose-built to centralise and optimise security data retention. By separating storage from compute, it enables:
Affordable, long-term storage (up to 12 years)
Scalable ingestion across Microsoft and third-party platforms
Continuous access to historical data for analytics and investigations
The solution unifies telemetry from:
Microsoft Defender XDR
Microsoft 365
Azure, Entra ID, Purview, and Intune
Over 350 third-party integrations (e.g., AWS, GCP)
This consolidation eliminates data silos and empowers a more contextual, AI-ready foundation for threat detection and response.
Cost Optimisation and Efficiency Gains
Sentinel Data Lake addresses the rising cost of SIEM operations by introducing flexible data retention strategies:
Hefty savings by offloading high-volume logs (e.g., firewall, DNS, proxy) to the Data Lake
A reduction in overall SIEM spend through tier consolidation and removal of third-party storage solutions
Additional savings by shifting lower-priority logs from the Analytics tier to the Data Lake
Storage Tiers Explained
Analytics Tier
Designed for real-time detection, alerting, and rapid querying
Suited for high-fidelity data such as Defender alerts and EDR logs
Retention: 90 days std
Data Lake Tier
Optimised for long-term retention at scale
Ideal for logs supporting compliance, forensics, and retrospective threat hunting
Ingested Analytics-tier data is automatically mirrored into the Data Lake without added cost
For teams currently relying on Azure Data Explorer (ADX) or exporting logs to Blob Storage for long-term retention or advanced analytics, Sentinel Data Lake represents a major shift. It potentially eliminates the need for custom export pipelines, external data transformations, and manual storage management by offering an integrated, cloud-native solution within Microsoft Sentinel.
Or dose it?
With automatic mirroring from the Analytics tier, cost-effective retention up to 12 years, and built-in querying via KQL and notebooks, security teams can now centralize log storage and analysis without sacrificing performance or context streamlining operations and reducing both complexity and cost.
Advanced Analytics and AI Integration
Sentinel Data Lake supports next-generation analysis capabilities:
Kusto Query Language (KQL): Enables in-depth, cross-timeframe investigations directly within the Defender portal
Jupyter Notebooks & Spark: Allows advanced pattern recognition, behavioural analytics, and AI model training using Python and Apache Spark
AI-Optimised Foundation: Microsoft Security Copilot and other AI solutions benefit from the broader context provided by long-term data availability
Strategic Use Cases
Sentinel Data Lake enables a wide range of operational and strategic capabilities that empower security teams to conduct more effective investigations, meet compliance obligations, and adapt to emerging threats.
Retrospective Threat Hunting: Correlate new threat intelligence with historical logs to identify previously undetected indicators of compromise.
Cost-Efficient Investigations: Conduct deep forensic analysis without incurring high compute costs by querying archived logs directly in the Data Lake.
Audit and Compliance: Meet regulatory and governance requirements by retaining data for up to 12 years in a secure and accessible format.
Behavioural Analysis: Use long-term telemetry to model normal activity and detect behavioural anomalies across users, devices, or applications.
Insider Risk Monitoring: Detect subtle insider threats that manifest over long periods, such as slow data exfiltration or privilege misuse.
Threat Actor Attribution: Compare activity patterns across timeframes to identify repeat behaviours tied to specific adversaries or campaigns.
Security Control Validation: Validate the effectiveness of controls over time by examining pre- and post-implementation behaviour or coverage.
Example Scenario: Delayed Detection with Retrospective Hunting
A zero-day vulnerability exploited by a nation-state actor is disclosed 10 months after its use in the wild. Using Sentinel Data Lake, the SOC team can run retrospective queries across historical logs to identify whether the vulnerability was exploited in their environment—even if it was not known at the time. Because the data is retained cost-effectively and accessible via KQL or Jupyter notebooks, the investigation can proceed without impacting operational SIEM performance or requiring third-party data recovery.
Adoption Prerequisites and Considerations
To use Sentinel Data Lake, ensure the following:
Access via the Microsoft Defender portal - Have you enabled unified RBAC yet?
Appropriate roles: Azure Subscription Owner, Microsoft Entra Global Administrator or Security Administrator, Log Analytics Contributor, Security Reader, and Security Operator
Workspaces must align with the Entra tenant’s region
Understand that new billing meters will apply
Be aware that historical data migration is not automatic—mirroring begins only after activation
Benefits for Existing Sentinel Users
If you are already using Microsoft Sentinel:
Data in the Analytics tier is automatically mirrored to the Data Lake tier at no additional charge
Improved table management and tier configuration are available via the Defender portal
Auxiliary logs can be consolidated within the Data Lake, reducing reliance on external tools
Platform Limitations
While highly capable, Sentinel Data Lake has defined constraints:
It does not replace the real-time detection capabilities of the Analytics tier
Historical data prior to activation is not migrated
Certain logs (e.g., EDR) must remain in the Analytics tier for immediate visibility
It is not designed for real-time dashboards or interactive visualisations
5-Step Guide to Assessing Data and Starting with Sentinel Data Lake
Before activating Sentinel Data Lake, it’s essential to assess your current data strategy against compliance, threat detection, and operational requirements. Follow this five-step guide to ensure a successful transition:
Step 1: Map Your Data Sources
Inventory all data sources currently ingested into your Microsoft Sentinel environment. Categorise them by purpose (e.g., security detection, compliance reporting, operational metrics) and determine their current retention period.
Step 2: Align with Detection and Compliance Needs
Review your analytics rules, threat detection use cases, and regulatory obligations. Identify which logs are:
Required for real-time alerting (keep in the Analytics tier)
Needed for long-term compliance or investigation (move to or retain in the Data Lake tier)
Step 3: Identify High-Volume, Low-Frequency Logs
Flag logs that contribute to high storage costs but are rarely queried in real-time (e.g., DNS, proxy, firewall). These are prime candidates for long-term retention in the Data Lake tier.
Step 4: Plan Activation and Communication
Understand that historical data will not be backfilled—only new data will be mirrored from the moment Data Lake is enabled. Prepare your team by updating documentation, alerting logic (where needed), and communication plans.
Step 5: Monitor, Review, and Optimise
After activation, regularly assess retention settings, billing impacts, and Data Lake usage. Adjust DCRs (Data Collection Rules) and table-level settings as needed to ensure cost efficiency and coverage.
Wow, that was a lot of information! A step-by-step getting started video will be published in the next few weeks, alongside upcoming content covering:
Design considerations and deployment patterns
Data tiering strategies based on table types
Automation, transformations, and retention scripting
Are you planning to enable Sentinel Data Lake in your environment?
Are you planning to enable Sentinel Data Lake in your environment, or are you waiting for additional features or use cases to mature? What’s holding you back, or accelerating your move?
Let us know how you intend to get started, or why you’re not ready just yet.
Best
Marcus
#MicrosoftSecurity
#MicrosoftLearn
#CyberSecurity
#MicrosoftSecurityCopilot
#Microsoft
#MSPartnerUK
#msftadvocate